There are numerous OCR libraries for python. tesserocr is the only library I found that has a decent, humanly-approachable API.
In this blog post we’ll use tesserocr to extract text from a nutrition facts image.
What is it exactly?
tesserocr is a simple, Pillow-friendly, wrapper around tesseract-ocr API.
Pillow is a friendly PIL fork (PIL is the Python Imaging Library).
Demo
We’ll extract text from this image:
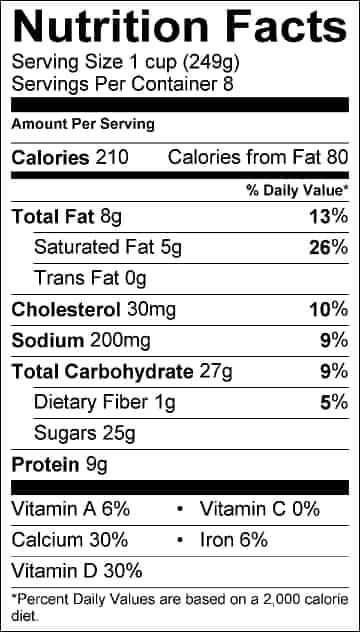
First, install all the requirements:
$ sudo apt install tesseract-ocr \ |
Now run the following gist:
from tesserocr import PyTessBaseAPI |
And viola!
$ python ocr.py /path/to/chocolate.jpg |